A few years ago I heard about a new database project called DuckDB, a new kind of database embracing columnar storage over the traditional row storage. The other thing, possibly the main thing at the time, was that it was designed to be embedded in your application. Even better it was developed in C++ and seemed to have extensive API coupled with a permissive license.
Looking Back
I started out writing stuff using what was the typical (at the time) LAMP stack where the database was always MySQL. At Kitware I was the principal investigator for an ambitious project developing three applications to really move computational chemistry forward. One of those projects was called MongoChem and it was a Qt, VTK, MongoDB based cross-platform desktop application I wrote about in a blog post.
We did some really cool work in that project but ultimately the approach of using MongoDB in a desktop application was flawed. At the time document stores were new and interesting approaches and MongoDB showed a lot of promise. The use of BSON, JSON and related technologies seemed like a great approach but the C++ drivers/support were weak, the licensing of the database restrictive (even more so nowadays) and support for custom operators for chemistry never materialized.
DuckDB Today
In my trusty test project I decided to see if I could get DuckDB working in a few hours. First hitch was the lack of a vcpkg package so I figured I could skip that for now and just build it. There is a makefile they tell you to use but I just used cmake directly. It seems to be a trend in projects to put something in front of cmake to make things easier, I think a lot of that is improved of late with presets.
Once built their C++ API seemed a little sparse, first question was how to find it from my project so that I could include the header and link to it. I took a guess after looking in the build tree and then tweaked it a few times until I came up with:
find_package(DuckDB CONFIG REQUIRED)
# This is just for DuckDB...their config file doesn't find Threads.
find_package(Threads REQUIRED)
I was then able to add a link to duckdb (there is no namespaced version) and include the header. The other major difference I noticed was that everything is in a duckdb namespace and the examples don’t use that. The first example almost works but the success variable is also protected. No matter, I got where I wanted to in the end. I was able to wrap the API in a small class in a C++ module and run a few queries.
Test Driven
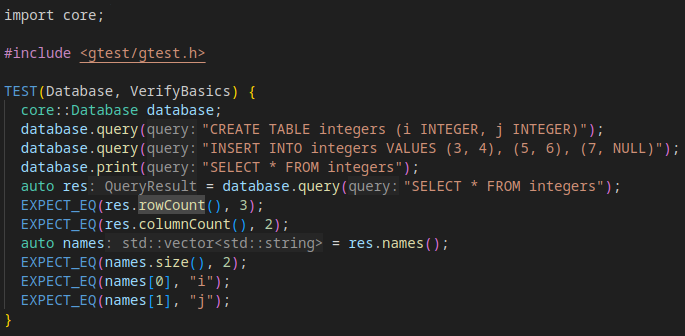
As this is just early exploration I find the easiest way to explore the capabilities is to add a few tests to validate my understanding and explore capabilities. I added a simple test as I fleshed out the class a little to create an in-memory database, insert a few rows and then read them back. The examples didn’t offer as much depth as I might have liked but the test suite and the C API docs both offered some pointers.
import core;
#include <gtest/gtest.h>
TEST(Database, VerifyBasics) {
core::Database database;
database.query("CREATE TABLE integers (i INTEGER, j INTEGER)");
database.query("INSERT INTO integers VALUES (3, 4), (5, 6), (7, NULL)");
database.print("SELECT * FROM integers");
auto res = database.query("SELECT * FROM integers");
EXPECT_EQ(res.rowCount(), 3);
EXPECT_EQ(res.columnCount(), 2);
auto names = res.names();
EXPECT_EQ(names.size(), 2);
EXPECT_EQ(names[0], "i");
EXPECT_EQ(names[1], "j");
}
It Works!
It works (commit db02c0f) and it didn’t take long although admittedly it doesn’t do much either! One of the things I liked about MongoDB was BSON, the ability to insert and retrieve typed binary data efficiently. I find myself looking at the DuckDB and wondering what the best way to get at the binary to insert into and retrieve columns efficiently might be. There are methods labeled as slow for retrieving single values, and I see an appender that lets me insert rows one at a time.
The other cool thing I knew about DuckDB is Apache Arrow support for the memory format used. I want to explore the arrow APIs more another time, last year there was a post about using Arrow Database Connectivity with DuckDB that looks promising, and links to some more C++ documentation using this as a way of working with DuckDB. I also really like the form of the Python example and the Arrow table API looks like something I would like to work with. Another thing I think arrow offers is binary across languages such as C++ and Python when most previous work ended up back in text (or JSON, same difference) at various points.
Getting Column Based
This is where I still feel a little out of my element and need to do some more reading and/or experimentation. Much of my earlier work very much focused on documents or rows, but I felt the pain and was looking to get back to something more structured. I had been wanting to dive into columnar storage more as a huge pain point was often a rich data model where any given element wanted a subset of columns very quickly and especially in C++ it was much more natural to access columns of a single concrete type.
I actually adopted something similar in the core data model for Avogadro 2 where I realized that a complex application supports many optional properties. The molecule class is a series of arrays that may or may not be initialized that represent properties on the molecule, the atoms or the bonds. Thinking aloud I would love to map some of this to modern columnar databases and arrow formats. That way I could efficiently store and retrieve various properties and use joins in a natural way to represent some of the optional columns.
Conclusions
It was great to see how quickly I could link to and start using DuckDB. I think I want to do something fairly outside of the majority use case hence the sparsity of the docs. I really like the idea of embedding something like DuckDB in an application but need to figure out some of the fast paths to get data in and out without hitting text conversion which really destroyed performance in previous work too. I also want to get my head around some of the complex data types that I could use to embed chemical data into columns such as arrays, lists, or packing binary in there.
The other thing I want to explore more deeply is the use of images in the Apache Arrow ecosystem, a lot of my previous work looked at 3D tomography and while at the synchrotron this was one of the larger data challenges. At present most things are stored in TIFFs, possibly in HDF5 files neither of which feel like the best approach in this day and age. I have seen some great work with images, but these are more 8, 16 and 32 bit intensity values (single component) and the load/save cycles were always far slower than I felt they should be.
Disclaimer
These are things I have been wanting to dig into for a while but my new role at Voltron Data means I now work with some of the people involved in these projects. This is more personal exploration and learning, I should probably ask some of these folks about the best approach but wanted to see what I could find on my own first. Back when I started working on MongoChem I thought there was real value in a desktop application that had all the power of a database behind it, but the interactivity of a desktop application coupled with hardware accelerated visualization.
Long winded way of saying this post is something on my own time and I haven’t asked anyone about the best approach. They may well be horrified at the path I found and I am not yet satisfied with it. Most results were for other languages, with the vast majority being straight up SQL or Python. Everything you see is my brief exploration with no input and I am certain I have colleagues who could put something together much more impressive in a fraction of the time.